
Machine Learning Suite for IIIF Resources
- Hosting-Organisationen
- Österreichische Nationalbibliothek - Abt. für Forschung u. Entwicklung
- Verantwortliche Personen
- Christoph Steindl
- Beginn
- Ende
GLAM-Institutionen wie die Österreichische Nationalbibliothek (ÖNB) sind für die Archivierung einer großen Anzahl von Objekten und Daten verantwortlich. Viele Informationen über diese Objekte sind in digitaler Form verfügbar, und in vielen Fällen ist das Objekt selbst bereits digitalisiert. Um diese Datensammlungen zu verwalten, zu erforschen und zu analysieren, wurden Ansätze des maschinellen Lernens (ML) entwickelt, um neue Informationen zu extrahieren und so neue Sichtweisen auf bestimmte Sammlungen zu schaffen.
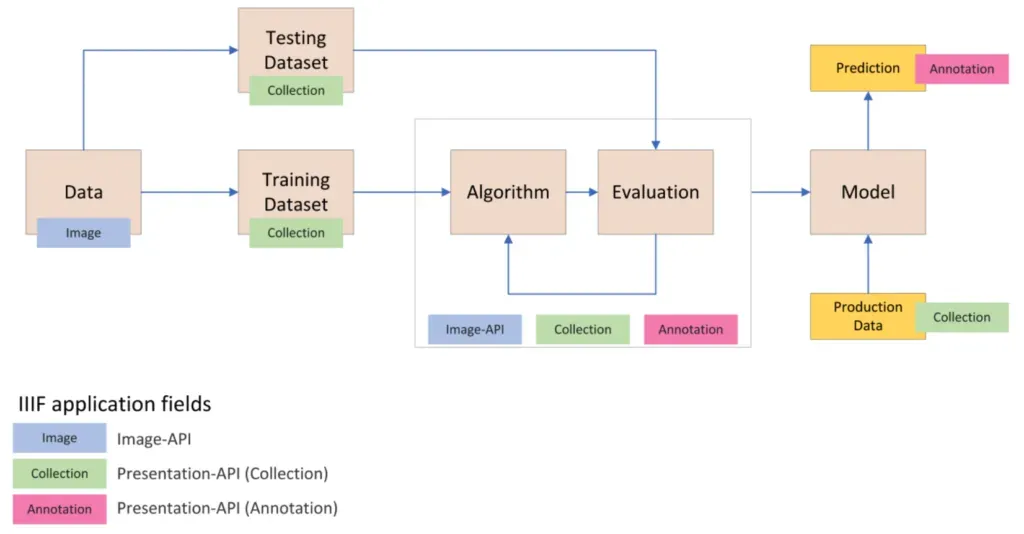
Viele GLAM-Institutionen nutzen das International Image Interoperability Framework (IIIF) , um den Zugang zu Metadaten und digitalem Material zu ermöglichen. IIIF ermöglicht eine einfache Integration digitaler Ressourcen in Websites und die gemeinsame Nutzung durch verschiedene Institutionen in Sammlungen und Arbeitsabläufen. Daher sind IIIF-fähige Daten ideal für Anwendungsfälle mit ML. Die folgende Grafik veranschaulicht die Phasen eines herkömmlichen ML-Workflows (siehe den Original-Workflow für maschinelles Lernen hier ) und die potenziellen Anwendungsbereiche des IIIF-Frameworks (d. h. verschiedene IIIF-APIs) darin.
Viele ML-Pipelines, die öffentlich zugänglich sind (z. B. auf GitHub), verwenden Jupyter-Notebooks, um ihre Modelle zu entwickeln, zu testen und anzuwenden. Jupyter-Notebooks sind auch in der DH sehr verbreitet, insbesondere um die Erstellung, Bearbeitung oder Analyse von Datensätzen zu dokumentieren. Darüber hinaus werden Jupyter-Notebooks zur Erfüllung von Lehraspekten eingesetzt. So hat beispielsweise das NewsEye-Projekt, das sich auf europäische Zeitungen konzentriert, eine Notebook-Sammlung mit einer eingehenden Analyse ihres Korpus (z. B. Textklassifizierung oder Textähnlichkeit) veröffentlicht, die für den Einsatz in Universitätskursen bestimmt ist.
Das Hauptziel dieses Projekts ist es, die verschiedenen Technologien - IIIF, ML, Jupyter Notebooks - zu kombinieren, um Forschende bei der Generierung neuen Wissens aus digitalisierten Kulturgütern zu unterstützen. Die Zusammenführung dieser Technologien hat viele Vorteile: (1) Es bietet eine einfache, standardisierte und wiederverwendbare Möglichkeit, IIIF-Materialien in ML-Anwendungen im Allgemeinen zu integrieren und (2) es veröffentlicht diese ML-Pipelines als Jupyter-Notebooks. Sie werden (3) gut dokumentiert sein und können daher (4) als Rohmodell für neue Projekte verwendet werden und (5) leicht von anderen Institutionen, die IIIF für ihre Daten unterstützen, eingesetzt werden. Zusätzlich zum rohen Quellcode zielt das Projekt auch darauf ab, interaktive Widget-Komponenten in den Notebooks zu verwenden, um die Software-Suite für Benutzer mit weniger Vorkenntnissen in den Computerwissenschaften einfach nutzbar zu machen.
Anwendungen des maschinellen Lernens sind und werden ein wesentlicher Bestandteil der Datenanalyse im wissenschaftlichen Kontext sein. Unabhängig davon, ob kleine Datensammlungen oder Big Data verarbeitet werden, ist es notwendig, die Nutzer im Umgang mit maschinellen Lernmodulen zu schulen. Auf diese Weise ist es möglich, komplexe und multidimensionale Probleme zu verstehen und so neue Einblicke in Sammlungen zu gewinnen. Das Projekt ermutigt dazu, diese innovativen Methoden auf bereits digitalisierte Daten anzuwenden.
Outcomes
Ziel des Projekts ist es, mehrere kleine Applikationen zu erstellen, um Anwendungen des maschinellen Lernens im GLAM-Bereich zu veranschaulichen, die IIIF-Ressourcen als Datensatz verwenden und für die potenziellen Nutzer einfach zu verwenden sind oder an ihren Anwendungsfall angepasst werden können, um so die Schwelle für maschinelles Lernen im Bereich der digitalen Geisteswissenschaften zu senken.
Für den Zugriff auf die IIIF-API, d. h. Extraktion, Download und Handhabung von Ressourcen, wurde eine kleine Bibliothek in Python erstellt, um die Handhabung von Manifesten, Sammlungen und Bildern zu vereinfachen. Darüber hinaus wurden die Beispielprojekte als Jupyter-Notebooks mit interaktiven Komponenten oder als Gradio-Applikationen (Python-Bibliothek zur interaktiven Demonstration von Anwendungen des maschinellen Lernens) zur Verfügung gestellt. Dies garantiert eine leichte Wiederverwendbarkeit der entwickelten Komponenten und eine einfache Nutzung der entwickelten Anwendungsfälle, auch für nicht-technische Benutzer.
Als konkreter Anwendungsfall wurde ein bestehender Code zur Bildfärbung mittels Deep Learning adaptiert und in Form eines Jupyter-Notebooks zur Verfügung gestellt. Die Anwendung verwendet Schwarz-Weiß-Postkarten aus der ÖNB Akon Collection , die über IIIF verfügbar sind, und färbt diese mit einem bestehenden und frei verfügbaren Modell ein und stellt das Ergebnis dem Nutzer als Download zur Verfügung. Ein anderes Notebook gibt dem Benutzer die Möglichkeit, ein Kolorierungsmodell zu trainieren, indem er eine IIIF-Bildersammlung verwendet und es dann auf ein Bild anwendet. Eine andere Anwendung bietet eine Benutzeroberfläche in Gradio, die einen Link zu einem IIIF-Manifest als Eingabe verwendet. Die lokal heruntergeladenen Bilder des Manifests können dann einzeln ausgewählt werden, um eine Bildklassifizierung mit dem Resnet18-Modell durchzuführen.
Für einen weiteren Anwendungsfall wurde auch eine Jupyter-Applikation für die automatische Extraktion von Bildern aus allen über IIIF zugänglichen Ressourcen entwickelt. Die Anwendung verwendet ein YOLOv8-Modell zur Bildsegmentierung und wurde an sechs Büchern aus der ABO-Sammlung (ca. 1200 Seiten) trainiert, die von Hand annotiert wurden. Durch die Angabe eines Links zum entsprechenden IIIF-Manifest können Bilder aus jedem Werk extrahiert und dann als Zip-Datei heruntergeladen werden. Darüber hinaus werden die Bereiche der erkannten Bilder als Anmerkungen an das Manifest angehängt, das dem Benutzer ebenfalls zur Verfügung gestellt wird.
Der Code der vier entwickelten Jupyter-Notebooks/Gradio-Anwendungen ist im GitLab Repositorium der ÖNB Labs frei verfügbar:
- https://labs.onb.ac.at/gitlab/a.rabensteiner/train_postcard_colorizer (Training eines Colorizer-Modells)
- https://labs.onb.ac.at/gitlab/a.rabensteiner/apply_postcards_colorizer (Anwendung eines vortrainierten Colorizer-Modells auf eine zufällige Postkarte aus der AKON-Sammlung)
Die Repositories enthalten die Jupyter-Notebooks und die für die Ausführung der Python-Programme erforderlichen Daten. Die Repositorien enthalten in der Regel ein Readme für die Dokumentation, eine Lizenz für die Weiterverwendung und eine Requirements-Datei mit allen externen Bibliotheken und Dependencies. Sofern möglich, wird auch ein Link bereitgestellt, um das Projekt als interaktiven Webcontainer (unter Verwendung der Requirements-Datei) in der Binder-Infrastruktur verfügbar zu machen.
Die Bildkolorierungsanwendungen liefern gute Ergebnisse auf den schwarz-weißen AKON-Postkarten, wie die folgenden vier Beispiele zeigen:

Darüber hinaus läuft die Anwendung des Colorizer-Modells auch in einem Binder-Container ( hier ) und kann dort direkt im Browser ohne vorherige Installation von Python und den notwendigen Bibliotheken verwendet werden.
Leider liefert die Anwendung zur Bildklassifikation mit Resnet18 keine zufriedenstellenden Ergebnisse für historische Ressourcen im Bibliothekskontext, da das Modell ursprünglich auf die Erkennung von 1000 Alltagsgegenständen trainiert wurde und keine Zeit auf die Konzeption und Sammlung eigener Annotationen verwendet wurde. Im Folgenden wird zum Beispiel die Klassifizierung eines Porträts als Fernseher dargestellt:
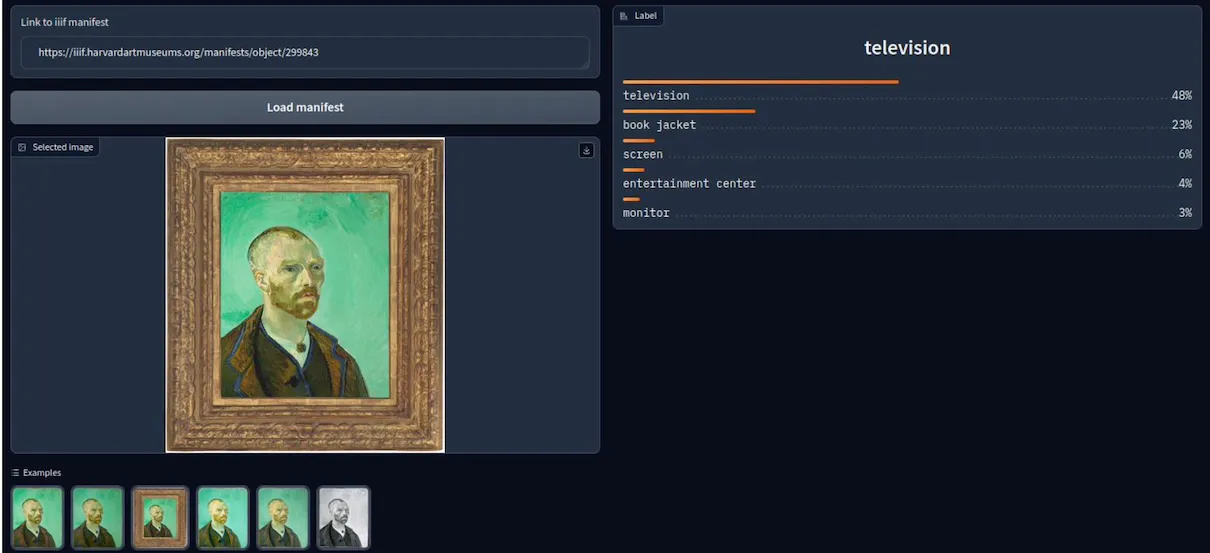
Nichtsdestotrotz dient die entwickelte Anwendung als Blaupause für den Einsatz eines solchen Modells auf IIIF-Daten, wo mit moderneren Ausgangsdaten zufriedenstellende Ergebnisse erwartet werden können. Der entsprechende Code ist verfügbar via: https://labs.onb.ac.at/gitlab/a.rabensteiner/resnet18_classifier_gradio
Das Jupyter-Notebook zur Extraktion von Illustrationen aus historischen Büchern mittels eines selbst trainierten Modells liefert nach Tests mit Ressourcen aus dem ABO-Korpus der ÖNB gute Ergebnisse, wie die folgenden Beispiele von Werken aus verschiedenen Epochen zeigen (Illustrationen vom Modell mit grünem Begrenzungsrahmen identifiziert):

Der entsprechende Code ist verfügbar via: https://labs.onb.ac.at/gitlab/a.rabensteiner/extract_figures_abo
Auch in diesem Fall kann das Notebook in einem Binder-Container ( hier ) verwendet werden, ohne Python und andere Bibliotheken zu installieren.
Alle vier Anwendungen (Kolorierung, Training des Kolorierungsmodells, Bildklassifizierung mit Resnet18 und Extraktion von Bildern) verwenden IIIF-Manifeste oder -Sammlungen zur Identifizierung und Verarbeitung von Werken. Daher wurde im Rahmen der Arbeit eine kleine Bibliothek zum Laden, Verarbeiten und Kommentieren von IIIF-Ressourcen erstellt, die in jeder der vier Anwendungen enthalten ist (z. B. hier ).
Die Projektergebnisse sind im GitLab der ÖNB Labs verfügbar: https://labs.onb.ac.at/gitlab/explore/projects/topics/CLARIAH-AT
Darüber hinaus wurde eine Projektbeschreibung als Dokumentation in Form eines Artikels auf ÖNB Labs veröffentlicht, abrufbar unter: https://labs.onb.ac.at/en/topic/iiif-jupyter/
Außerdem wurden die Repositorien und Teilprojekte in der GLAM-Community beworben und Sammlungen für Tutorials aus dem Bereich Digital Humanities (DH) verlinkt, wie z.B. https://glamlabs.io/computational-access-to-digital-collections/