
Machine Learning Suite for IIIF Resources
- Hosting organisations
- Österreichische Nationalbibliothek - Abt. für Forschung u. Entwicklung
- Responsible persons
- Christoph Steindl
- Start
- End
Project lead: Christoph Steindl
Institution: Austrian National Library (ÖNB)
Project duration: 01.06.2023 – 30.11.2023
GLAM institutions like the Austrian National Library (ÖNB) are responsible for archiving a vast amount of objects and data. Much information about these objects is available in digital form, and in many cases the object itself is already digitized. To manage, explore and analyze these collections of data, machine learning (ML) approaches have been developed to extract new information in order to create new views on certain collections.
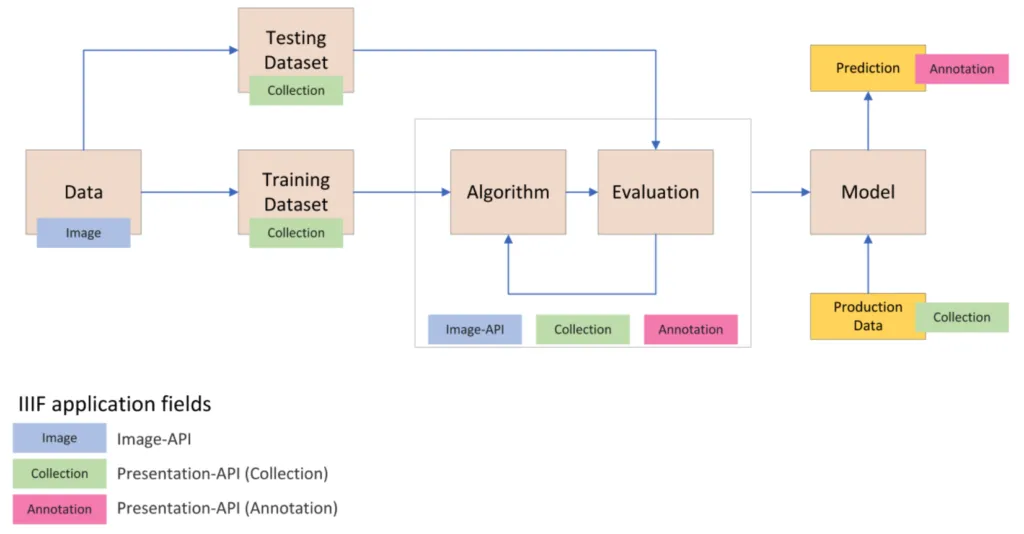
Many GLAM institutions use the International Image Interoperability Framework (IIIF) to give access to metadata and digital material. IIIF allows for an easy integration of digital resources in websites and sharing across different institutions in collections and workflows. Thus IIIF-ready data is ideal for use cases with ML. The following graphic illustrates the stages of a conventional ML workflow (see the original machine learning workflow here) and the potential areas of application of the IIIF framework (ie. different IIIF APIs) within.
Many ML pipelines that are publicly available (e.g. on GitHub) use Jupyter notebooks tot rain, test and apply their models. Jupyter notebooks are also very common in DH, in particular to document the generation, manipulation or analysis of datasets. In addition, Jupyter notebooks are used to fulfill teaching aspects. As an example, the NewsEye project with a focus on European newspapers published a notebook collection with an in-depth- analysis of their corpus (e.g. text classification or text similarity) dedicated for the use at university courses.
The main goal of this project is to combine the different technologies – IIIF, ML, Jupyter notebooks – in order to support researchers in generating new knowledge from the digitized cultural assets. Bringing together these technologies has many benefits: (1) it provides an easy, standardized and reusable way to integrate IIIF materials into ML applications in general and (2) it publishes these ML pipelines as Jupyter notebooks. They will be (3) well documented and can therefore (4) be used as a boilerplate for new projects and (5) can easily be applied by other institutions that support IIIF for their data. In addition to raw source code the project also aims to use interactive widget components in the notebooks in order to make the software suite easy to use for users with less previous knowledge in computer sciences.
Machine learning applications are and will be an essential part of data analysis in the scientific context. Regardless of whether small data collections or big data are processed, it is necessary to train users to use machine learning modules. This way, it is possible to understand complex and multidimensional problems and thus create new insights into collections. The project encourages applying these innovative methods to already digitized data.
Outcomes
The aim of the project is to create several small applications to illustrate machine learning applications in the GLAM area, which use IIIF resources as a data set and are easy to use for the potential users or can be customised to their use case, thus lowering the threshold for machine learning in the digital humanities area.
For access to the IIIF API, i.e. extraction, download and handling of resources, a small library in Python will be created to simplify the handling of manifests, collections and images. In addition, the example projects are made available as Jupyter notebooks with interactive components or as Gradio applications (Python library for interactive demonstration of machine learning applications). This guarantees easy reusability of the developed components and simple utilisation of the developed use cases, even for non-technical users.
As specific use cases, an existing code for image colouring by means of deep learning was adapted and made available in the form of a Jupyter notebook. The application uses black and white postcards from the ÖNB Akon Collection, which are available via IIIF, and colours them using an existing and freely available model and the result to the user as a download. Another notebook gives the user the opportunity to train a colourisation model by using a IIIF collection of images and then applying it to an image. Another application provides a user interface in Gradio that uses a link to an IIIF manifest as input. The locally downloaded images of the manifest can then be selected individually to perform image classification using the Resnet18 model.
For another use case also Jupyter application has been developed for the automatic extraction of images from any resources accessible via IIIF. The application uses a YOLOv8 model for image segmentation and was trained on six books from the ABO collection (approx. 1200 pages), which were annotated by hand. By providing a link to the corresponding IIIF manifest, images can be extracted from any work and then downloaded as a zip file. In addition, the areas of the detected images are attached as annotations to the manifest, which is also made available to the user.
The code of the four developed Jupyter notebooks/radio applications is freely available as a repository in the GitLab of ÖNB Labs:
- https://labs.onb.ac.at/gitlab/a.rabensteiner/train_postcard_colorizer (training a colourizer model)
- https://labs.onb.ac.at/gitlab/a.rabensteiner/apply_postcards_colorizer (application of a pre-trained Colorizer model to a random postcard from the AKON collection)
The repositories contain the Jupyter Notebooks and the data required to run the Python programmes. The repositories generally contain a readme for the documentation, a licence for subsequent use and a requirements file with all external libraries and dependencies. Where possible, a link is also provided to make the project available as an interactive web container (using the requirements file) in the Binder infrastructure.
The image colourization applications deliver good results on the black and white AKON postcards, as can be seen in the following four examples:

In addition, the application of the Colorizer model also runs in a Binder container (here) and can be used there directly in the browser without prior installation of Python and the necessary libraries.
Unfortunately, the application for image classification with Resnet18 does not provide satisfactory results for historical resources in a library context, as the model was originally trained to recognise 1000 everyday objects and no time was spent on conceptualising and collecting own annotations. In the following, for example, the classification of a portrait as a television:
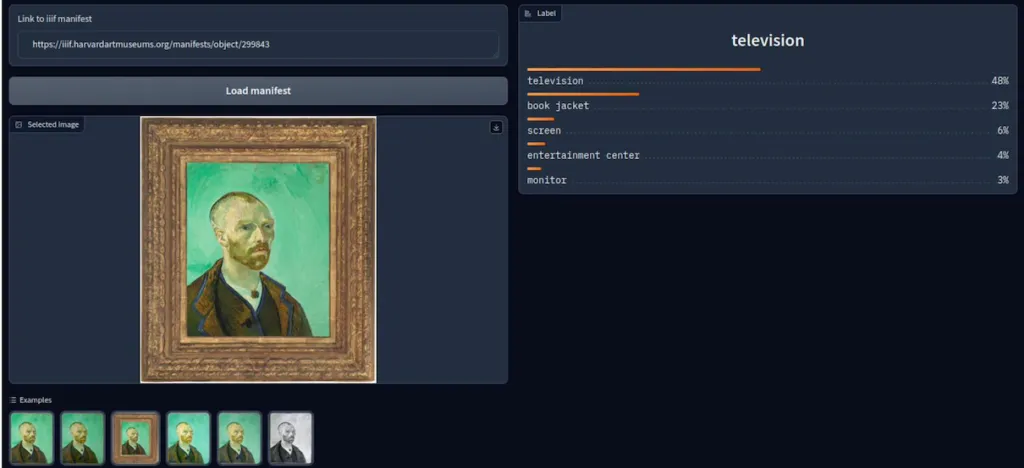
Nevertheless, the developed application serves as a blueprint for the use of such a model on IIIF data, where satisfactory results can be expected with more modern initial data.
The corresponding code is available at: https://labs.onb.ac.at/gitlab/a.rabensteiner/resnet18_classifier_gradio
The Jupyter Notebook for extracting illustrations from historical books using a self-trained model delivers good results after tests with resources from the ABO corpus of the ÖNB, as can be seen from the following examples of works from different periods (illustrations identified by the model with green bounding box):

The corresponding code is available at: https://labs.onb.ac.at/gitlab/a.rabensteiner/extract_figures_abo
Also in this case, the notebook can be used in a binder container (here) without installing Python and other libraries.
All four applications (colourisation, training of colourisation model, image classification with Resnet18 and extraction of images) use IIIF manifests or collections to identify and process works. Therefore, a small library for loading, processing and annotating IIIF resources was created as part of the work, which is included with each of the four applications (for instance, here).
The project results are available in the GitLab of the ÖNB Labs: https://labs.onb.ac.at/gitlab/explore/projects/topics/CLARIAH-AT
In addition, a project description has been published as documentation in the form of an article on ÖNB Labs, available at: https://labs.onb.ac.at/en/topic/iiif-jupyter/
Furthermore, the repositories and sub-projects were distributed in the GLAM community and collections for tutorials from the Digital Humanities (DH) area were linked, such as https://glamlabs.io/computational-access-to-digital-collections/