Esperanto Newspaper Excerpts
- Hosting organisations
- Austrian National Library (ÖNB)
- Responsible persons
- Simon Mayer
- Start
- End
Project lead: Simon Mayer
Institution: Austrian National Library (ÖNB)
Project duration: 1.4.2023 – 31.03.2024
The Project* Esperanto Newspaper Excerpts* deals with digitized newspaper excerpts about Esperanto, which are preserved in the Department of Planned Languages and Esperanto Museum of the Austrian National Library.
The collection contains excerpts from a wide array of newspapers from different countries in 22 languages. It is of significant interest to the Esperanto community because it allows to track the history and development of the language across time.
The goal of the project is to make the collection full-text searchable. Due to the complex layout of the newspaper articles, we employ a two-stage approach. First, a layout recognition model detects all text blocks. Second, each text block is passed to Optical Character Recognition (OCR) software which recognizes the individual letters. Our approach aims to solve the complex layout problem as well as the challenging multi-language nature of the data set. The results comprise a data set where each image is annotated with meta data and full text. The publication will adhere to the FAIR and Open Data principles and will be accessible via ONB Labs.
keywords: OCR, natural language processing, computer vision, machine learning
(intermediary) Outcomes
working stages in the project:

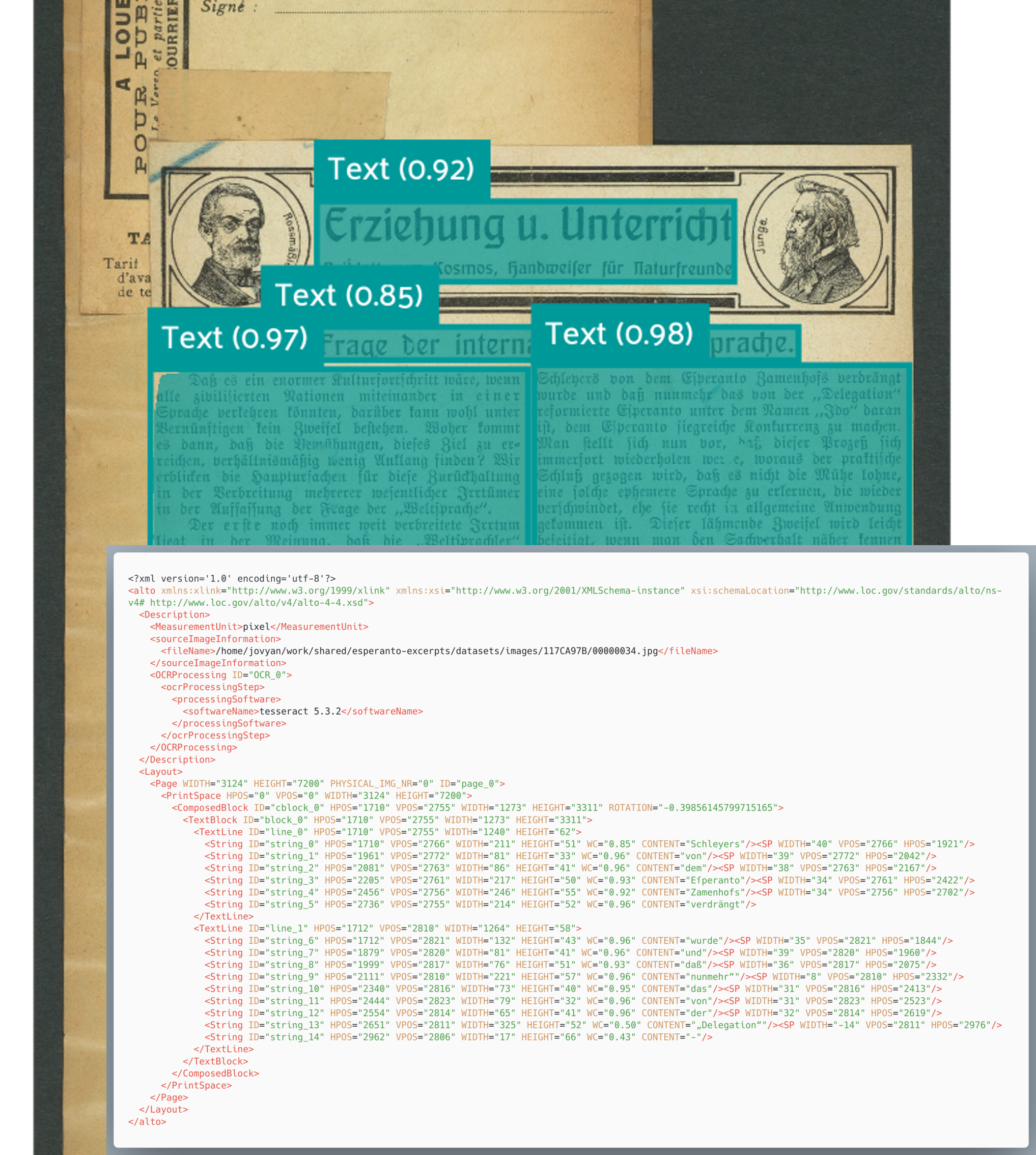
The image shows a section of an original scan of a newspaper article with a two-column layout.

The picture shows the result of the layout analysis, where relevant text boxes were recognised and marked.
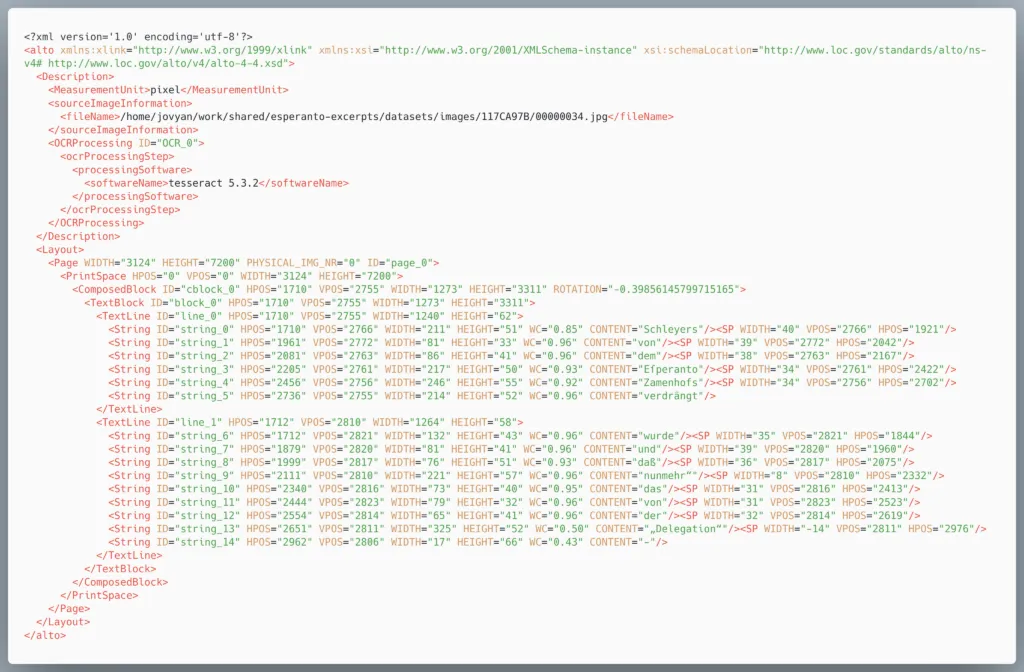
This picture shows a section of the generated ALTO-XML, where the beginning of the second column (“Schleyers von dem Esperanto Zamenhofs verdrängt wurde…”) can be read.