EventSearch API
- Hosting-Organisationen
- Österreichische Nationalbibliothek (ÖNB) und Österreichische Nationalbibliothek - Abt. für Forschung u. Entwicklung
- Verantwortliche Personen
- Max Kaiser
- Beginn
- Ende
Ereignisse sind allgegenwärtige Merkmale menschlichen Lebens zu allen Zeiten an allen Orten. Entsprechend unausweichlich trifft man auf Erwähnung und Dokumentation von Ereignissen in historischen wie zeitgenössischen Quellen, die Grundlage geisteswissenschaftlicher Forschung sind, ebenso wie in fiktionalen Texten. Die Zeugen können Lebensdokumente (Tagebücher, Reisenotizen) genauso sein wie amtliche Dokumente (Urkunden, Protokolle, Kalender) oder Kulturüberlieferungen materieller Natur (Inschriften, Teppiche o.a.). Werden diese Quellen und (fiktionalen) Texte digital ediert, hat sich zwar die Kodierung nach den Richtlinien der Text Encoding Initiative (TEI) durchgesetzt, jedoch fehlt eine gängige Praxis für die semantisch eindeutige Erfassung und Auszeichnung von Ereignissen. Hinzu kommt, dass zum Ereignis zugehörige grundlegende Informationen wie ein zeitlicher Hinweis, eine Lokalisierung oder die Angabe zu beteiligten Personen nicht ohne weiteres möglich ist. Im Projekt wird die Kodierung von Ereignissen im Rahmen der TEI modelliert. Dabei wird eine flache Auszeichnung angestrebt, um die Datenmigration für alle Editionsdaten so niedrigschwellig wie möglich zu halten. Selbstverständlich liegt es bei den EditorInnen zu definieren, was im Kontext der jeweiligen Edition ein Ereignis ist. Das vorgeschlagene Modell wird auf bestehende Editionsprojekte der Projektpartner angewendet, um so einen Minimalkorpus an EventSearch-Daten zu generieren.
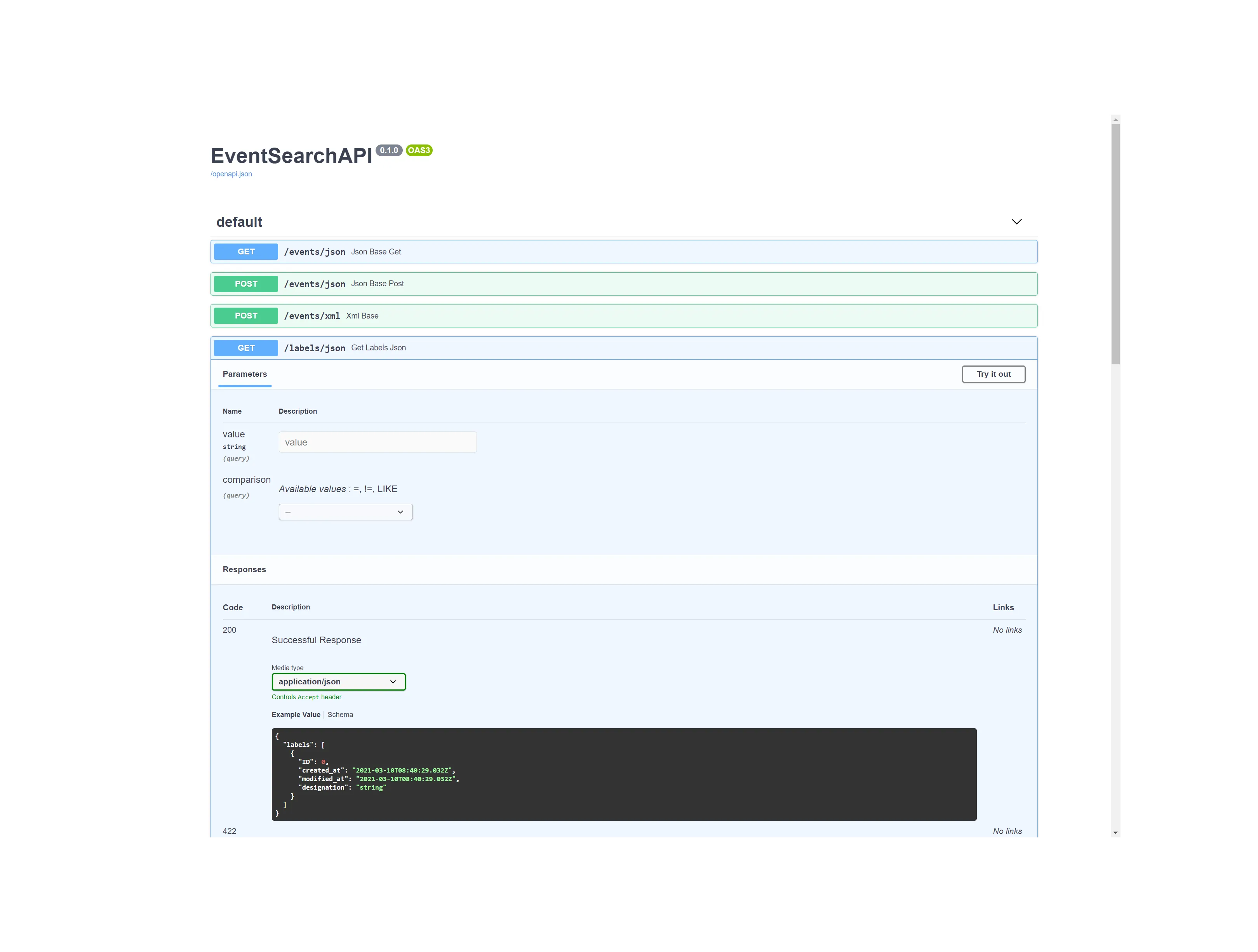
Mit EventSearch API wird eine maschinenlesbare Schnittstelle (API) für in digitalen Editionen markierte Ereignisse entwickelt. EventSearch ermöglicht es, die aufgezeichneten Ereignisse einzelner digitaler Editionen leichter auffindbar und durchsuchbarer zu machen. Über die EventSearch-Schnittstelle können automatisch Ereignisse aus digitalen Editionen, die in einem bestimmten TEI-Format kodiert sind, abgefragt werden und für weitere inhaltliche Analysen ausgewertet werden. Eine niederschwellige Möglichkeit zu partizipieren wird angeboten, sodass Editionsprojekte unabhängig von Größe und Budget ihre Ergebnisse teilen können.
Die Basisinfrastruktur der API wurde von September bis November 2020 um das Python-Framework FastAPI entwickelt. Die Schnittstelle mit Beispieldaten aus drei Projekten wird in Q2/2021 veröffentlicht. Die Dokumentation der Schnittstelle wird über das Swagger-Framework zur Verfügung gestellt.
Das Projekt wird in Kooperation mit der Österreichischen Akademie der Wissenschaften / Institut für die Erforschung der Habsburgermonarchie und des Balkanraumes (ÖAW/IHB) sowie der Universität Graz / Zentrum für Informationsmodellierung (ZIM-ACDH) durchgeführt. Es ist 2020 von CLARIAH-AT gefördert worden.