
Esperanto Newspaper Excerpts
- Hosting-Organisationen
- Austrian National Library (ÖNB)
- Verantwortliche Personen
- Simon Mayer
- Beginn
- Ende
Das Projekt Esperanto Newspaper Excerpt beschäftigt sich mit digitalisierten Zeitungsausschnitten über Esperanto, die in der Sammlung für Plansprachen und dem Esperantomuseum der Österreichischen Nationalbibliothek aufbewahrt werden.
Die Sammlung enthält Ausschnitte aus einer Vielzahl von Zeitungen aus verschiedenen Ländern und in 22 Sprachen. Die Erschließung des Bestandes ist für die Esperanto Community von großem Interesse, da dadurch die Geschichte und Entwicklung der Sprache über die Zeit hinweg verfolgt werden kann.
Das Ziel des Projekts ist es, die Sammlung textuell durchsuchbar zu machen. Aufgrund des komplexen Layouts der Zeitungsausschnitte haben wir uns für einen zweistufigen Ansatz entschieden. Zunächst identifiziert ein Layout-Erkennungsmodell alle Textblöcke. Danach wird jeder Textblock an Optical Character Recognition (OCR)-Software übergeben, die die einzelnen Buchstaben erkennt. Diese Vorgehensweise zielt darauf ab, das Problem des komplexen Layouts sowie die Herausforderungen der mehrsprachigen Natur des Datensatzes zu lösen. Die Ergebnisse bestehen aus mit Metadaten annotierten Bildern und dem Volltext, der erkannt worden ist. Die Resultate werden nach den FAIR- und Open-Data-Prinzipien über ONB Labs veröffentlicht.
Keywords: OCR, natural language processing, computer vision, machine learning
Outcomes
Arbeitsschritte im Projekt:

Die Abbildung zeigt einen Ausschnitt aus einem Original-Scan eines Zeitungsartikels mit einem zweispaltigen Layout.

Die Abbildung zeigt das Ergebnis der Layout-Analyse, bei der die relevanten Textfelder erkannt und markiert wurden.
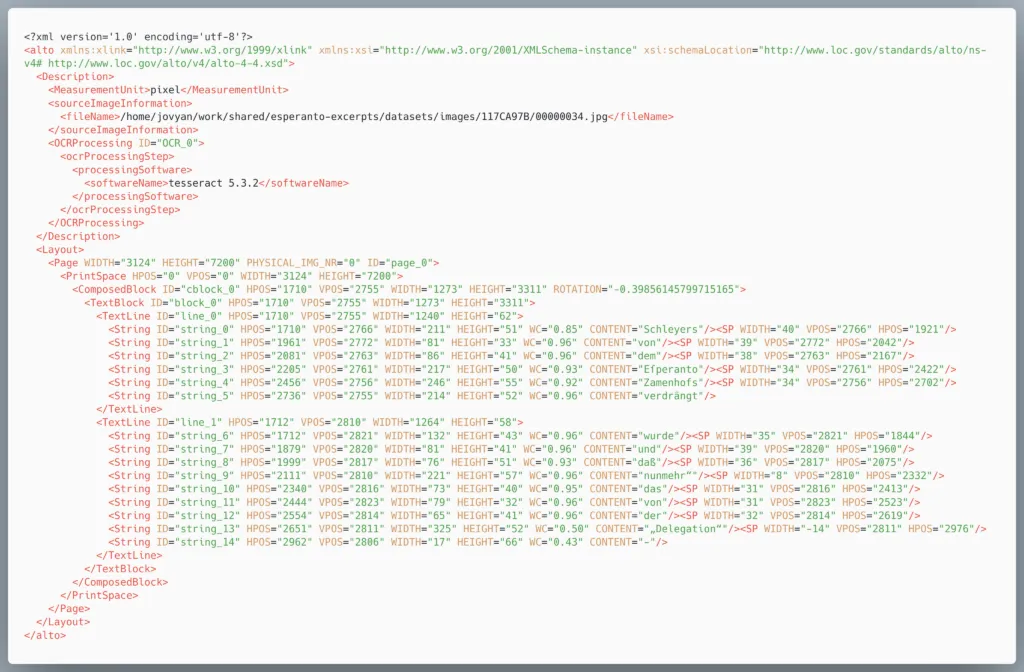
Dieses Bild zeigt einen Ausschnitt aus dem generierten ALTO-XML, in dem der Anfang der zweiten Spalte („Schleyers von dem Esperanto Zamenhofs verdrängt wurde…“) zu lesen ist.